Things
Untitled game(2024)
Working on my self-written engine+game, a wild mix of classic games I liked.
Starfield Navigator(2022)
A C++/OpenGL program that reconstructs and visualizes the starmap of the upcoming game Starfield.
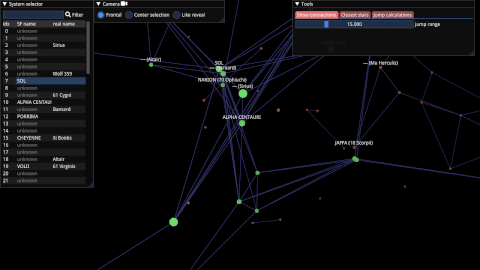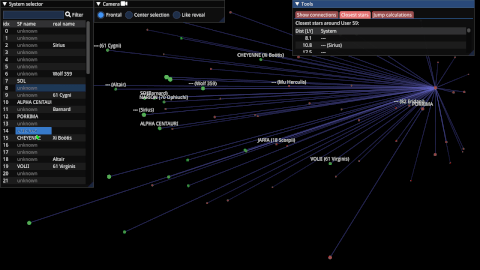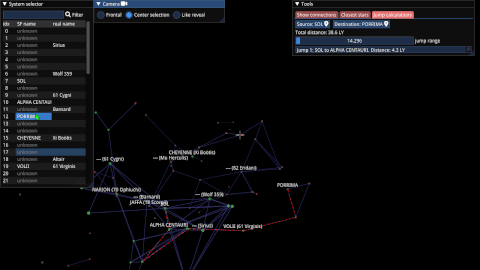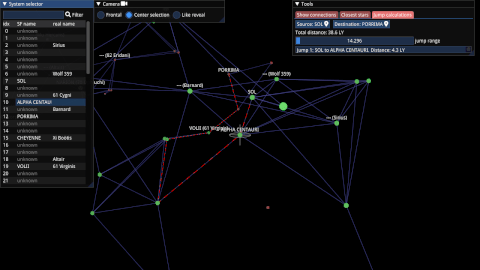
intrusive_optional(2022)
A C++20 header-only library that implements an optional type without the size overhead of std::optional.
Experimental concurrency(2022)
Performance experiments with C++ synchronization primitives. Exploring their latency properties; differences between CPU vendors and individual hardware cores.

oof (omnipotent output friend)(2021)
It's common for C++ programs to write output to the console. But consoles are far more capable than what they are usually used for. The magic lies in the so-called Virtual Terminal sequences: These cryptic character sequences allow complete control over position, color and other properties of written characters. Oof is a single C++20 header that wraps these in a convenient way.
It also offers a special interface with two special optimizations to make real-time pixel graphics displayed inside the console possible.

Binary bakery(2021)
There are many solutions for shipping assets or other binary data with an application. Almost all of them involve shipping at least one additional file together with the executable. Sometimes however you want to include binary data inside your source code. Binary Bakery does just that.
It provides a tool that translates arbitrary binary data to C++ source code. And a lightweight header that allows access to that data inside your code at compile-time! For images there's a special code-path that allows direct access to the pixel color data. There's also built-in support for data compression.
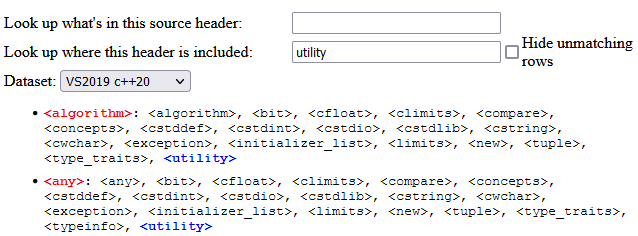
STL explorer(2021)
A small web tool that contains and presents information about the implicit include structure of the MSVC c++ standard headers. The standard library headers have internal includes just like all headers. By including <vector>, you're really also including 18 other headers.
This has great implications for compile times. Especially library authors often have to weigh for or against including certain headers - or finding another solution to keep the includes small. This tool can help.
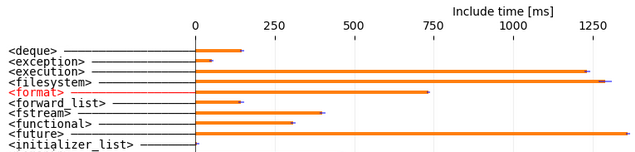
C++ Library Include Times (CPP-LIT)(2020)
Exact measurements on the include time of C++ standard library headers, measured with Visual Studio 2019.
Terminal moo(2020)
Terminal moo is a tiny game with a special technical premise: It runs entirely in a console window, abusing virtual terminal sequences to create real-time full-color graphics.

dt(2020)
Profiling code is usually done by either sampling or timing different code sections. But sometimes what you really want to know is how fast an application would run if a part of the code wouldn't run at all. That is not necessarily equal to the time that section takes to run. In particular because a code section impacts cache and other parts of the memory hierarchy and thereby negatively influences code that comes after
dt is a simple C++ library that facilitates such "differential profiling" and reports the results.

ofit: optical filter tool(2017)
A Python program I wrote during my thesis. With ofit you can chain arbitrary components of optical filters together, calculate the transfer matrix and draw the resulting design with TikZ.
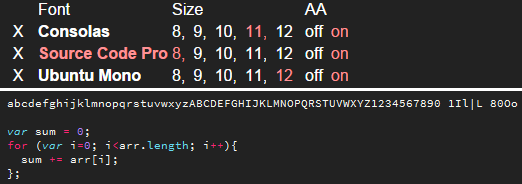
Programming font comparison(2016)
A webbased tool that compares about 50 different programming fonts. Every font is used with a range of font sizes, color themes, renderer and anti-alias settings.
The screenshots are taken in the Sublime Text editor. The process to capture the screenshots is automated with an autohotkey script which itself reads commands from a python-generated file. Imagemagick is used to extract the relevant part from the screenshots. The website is built with React.js
- GitHub Repo
- website: s9w.io/font_compare
3D DLA(2015)
Simulation of a 3D DLA process inside the browser. DLAs can be simulated with a boolean grid that starts with all zeros and a one in the middle. Particles spawn at some distance from the center and random walk until they are right next to another particle. The structure grows in a crystal-like way and can be used to calculate the fractal dimension.
The app contains both an asynchronous visualization and computation of a DLA process in javascript as well as a real-time computation of the fractal dimension. The WebGL output is powered by three.js and the chart is done with highcharts.
- GitHub Repo
- website: s9w.io/dla

magneto(2015)
A fast parallel C++ program for solving the 2D Ising Model. Implements Metropolis and Swendsen-Wang algorithms.
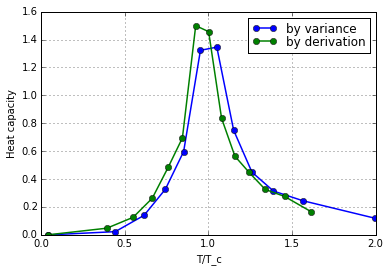
preTeX(2015)
A LaTeX preprocessor written in Python.
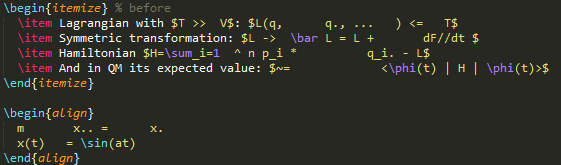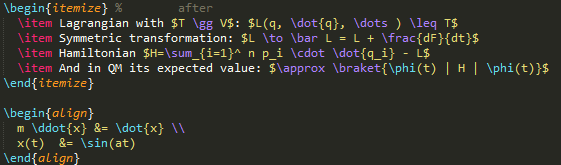
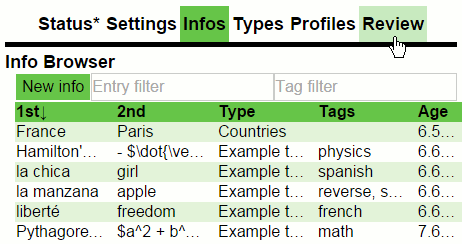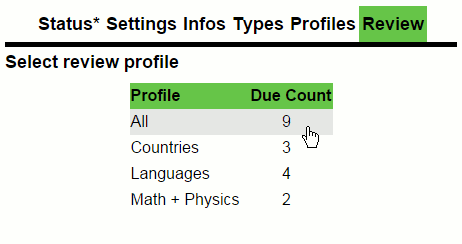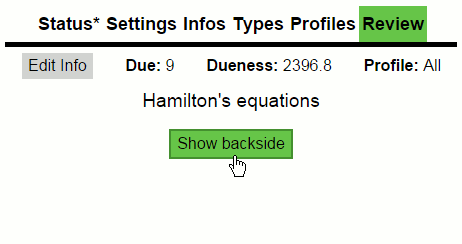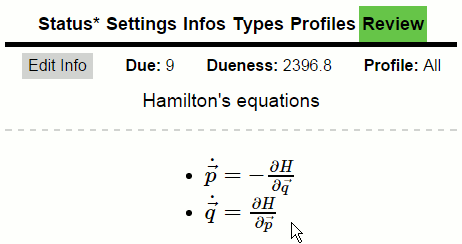
Ginseng(2015)
A web-app for spaced repetition learning. 100% clientside; UI done with React, data stored in local storage and sync over Dropbox.